

はじめに
生成AIの普及により、Webサイト運営の前提が大きく変わり始めています。
これまでWebサイトは、Googleなどの検索エンジンに正しくクロールされ、検索結果に表示されることを前提に設計されてきました。しかし現在は、検索エンジンだけでなく、生成AIやAIエージェントがWeb上の情報を読み取り、回答生成や学習、要約、比較、推薦に利用する時代になっています。
つまり、Webサイトの情報は「人に読まれるもの」であると同時に、「AIに読まれ、解釈され、再利用されるもの」になりました。
この変化は、企業サイト、メディア、ECサイト、SaaS、自治体サイトなど、あらゆるWeb運営者に関係します。AIに情報を見つけてもらうことは重要です。一方で、無制限に情報を取得されることには、著作権、ブランド毀損、収益機会の喪失、アクセス負荷といった課題もあります。
これからのWeb運営では、単に「検索に出る」だけでなく、「AIにどこまで読ませるか」「どの情報を許可し、どの情報を守るか」「AIとの関係をどのように収益化するか」を考える必要があります。
本記事では、AIクローラーの種類、robots.txtによる制御、著作権法との関係、今後の収益化モデル、そして企業が実務で確認すべきポイントを整理します。参照資料:
AIクローラーとは何か
AIクローラーとは、Web上のページを自動的に巡回し、情報を取得するプログラムのことです。
従来のクローラーは、主に検索エンジンがWebページを収集し、検索結果に反映するために使われてきました。代表的なものがGooglebotです。Webサイト運営者にとって、検索エンジンのクローラーに正しくページを読み取ってもらうことは、SEOの基本でした。
しかし、生成AIの時代に入ると、クローラーの目的が多様化しました。単に検索結果へ掲載するためだけでなく、AIモデルの学習、AI検索の回答生成、エージェントによる情報取得、リアルタイム要約などに使われるようになっています。
ここで重要なのは、すべてのAIクローラーが同じ役割ではないという点です。
たとえば、AIモデルの学習データを集めるクローラーもあれば、AI検索で最新情報を取得するためのクローラーもあります。また、ユーザーがAIブラウザやAIエージェントを通じてページを開く際に動くものもあります。
Webサイト側から見ると、「AIがアクセスしてきた」という一言では済ませられません。どのAIが、どの目的で、どの範囲の情報を取得しているのかを把握することが、これからのWebガバナンスの出発点になります。
AIクローラーには複数の種類がある
AIクローラーは、大きく分けると次のような種類に整理できます。
学習用クローラー
学習用クローラーは、生成AIモデルのトレーニングや改善に使うデータを集めるためのものです。
Web上の記事、FAQ、商品説明、専門情報、画像、構造化データなどが収集対象になる可能性があります。企業にとっては、自社の知見やコンテンツがAIの学習材料になることを意味します。
ここで問題になるのは、コンテンツの価値です。長年かけて蓄積した記事や専門情報が、無断でAIの学習に使われることに対して、抵抗を感じる企業やメディアは少なくありません。特に、有料コンテンツや専門性の高い記事を持つサイトでは、学習利用をどこまで許可するかを慎重に考える必要があります。
検索・回答生成用クローラー
検索・回答生成用クローラーは、AI検索やチャット型検索の回答を作るためにWeb情報を取得するものです。
ユーザーがAIに質問したとき、AIはWeb上の情報を参照し、要約した回答を提示することがあります。この場合、Webサイトへのリンクが表示されることもありますが、ユーザーが元記事まで訪問しないケースも増えます。
これはWeb運営者にとって大きな変化です。これまでは検索結果に表示され、クリックされることでアクセスが生まれていました。しかしAI検索では、回答がAI画面上で完結する可能性があります。いわゆる「ゼロクリック」の増加です。
情報提供者としての露出は増えても、サイト流入や広告収益につながりにくい。この構造を理解しておかなければ、従来型のSEO指標だけでは成果を正しく測れなくなります。
ユーザーエージェント型クローラー
ユーザーエージェント型のAIクローラーは、ユーザーの操作や依頼に応じてWebページを閲覧するものです。
たとえば、ユーザーがAIに「このページを要約して」「この商品を比較して」「この会社について調べて」と指示した場合、AIが代わりにWeb情報を読み取り、整理することがあります。
このタイプは、従来の検索エンジンクローラーとは少し性質が異なります。Webサイト側から見るとAIのアクセスですが、背後には人間の利用目的があります。そのため、単純にすべてをブロックすればよいとは限りません。
企業サイトにとっては、見込み客がAIを通じて情報収集する時代になるため、AIに正しく読まれる情報設計も重要になります。
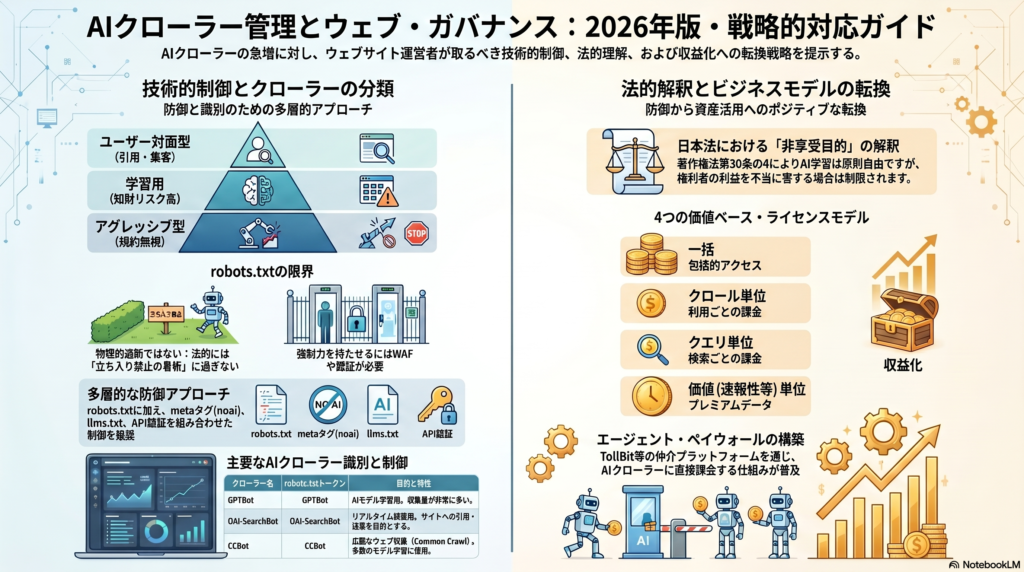
robots.txtはAIクローラー制御の基本になる
AIクローラーへの対応で最初に確認すべきものが、robots.txtです。
robots.txtは、Webサイトのルートディレクトリに設置するテキストファイルで、クローラーに対して「このページはクロールしてよい」「この領域はクロールしないでほしい」と伝えるために使われます。
たとえば、特定のクローラーに対して全ページの取得を拒否する場合、robots.txtにUser-agentとDisallowの指定を記述します。
ただし、robots.txtは万能ではありません。基本的にはクローラー側の自主的な遵守に依存する仕組みです。つまり、誠実なクローラーは指示に従いますが、悪質なクローラーや規約を守らないクローラーを完全に止める技術的な壁ではありません。
そのため、robots.txtは「入口のルール」として重要ですが、機密情報や有料情報を守るためには、認証、アクセス制御、WAF、IP制限、ログ監視などと組み合わせる必要があります。
AIクローラーをすべてブロックすべきではない
AIクローラーへの不安が高まると、「すべてブロックした方が安全ではないか」と考えたくなります。
しかし、これは必ずしも最善策ではありません。
AI検索やAIエージェントが普及すれば、ユーザーは従来の検索結果だけでなく、AIの回答を通じて企業や商品、サービスを知るようになります。そのとき、AIにまったく情報を読ませないサイトは、AI上で存在感を失う可能性があります。
たとえば、企業の基本情報、サービス内容、実績、FAQ、問い合わせ導線、採用情報などは、AIに正しく理解されることで新たな接点を生む可能性があります。
一方で、専門ノウハウ、有料記事、独自調査、会員限定資料、価格戦略に関わる情報などは、無制限に取得されると不利益につながるかもしれません。
重要なのは、「許可する情報」と「制限する情報」を分けることです。
これからのWeb運営では、AIに見つけてもらうための開放性と、事業資産を守るための管理性の両立が求められます。
著作権法との関係も無視できない
AIクローラーを考えるうえで、著作権法との関係も重要です。
日本では、情報解析やAI学習に関して、一定の範囲で著作物の利用が認められる可能性があります。ただし、だからといって、すべてのWebコンテンツが無条件に自由利用できるわけではありません。
特に、著作権者の利益を不当に害する場合や、アクセス制限を回避して情報を取得する場合、有料コンテンツを実質的に代替するような利用が行われる場合には、問題が生じる可能性があります。
Webサイト運営者にとって大切なのは、法的な解釈を一方的に決めつけないことです。
「AI学習だから問題ない」
「robots.txtに書けば完全に守られる」
「AIに使われたら必ず違法」
このように単純化して考えるのは危険です。
実務では、利用規約、robots.txt、メタタグ、会員認証、ログ記録、コンテンツ分類、契約条件などを組み合わせ、自社としての方針を明確にすることが必要です。
AIクローラー時代にはWebガバナンスが必要になる
これまでWebサイトの管理は、SEO、セキュリティ、更新運用、アクセス解析を中心に考えられてきました。
しかしAIクローラー時代には、そこに「Webガバナンス」という視点が加わります。
Webガバナンスとは、自社のWeb情報をどのように公開し、どのように使われることを許可し、どのようなリスクを管理するかを決める考え方です。
具体的には、次のような項目が含まれます。
・AIクローラーに読ませるページの整理
・robots.txtの定期確認
・AI向けに公開するFAQや会社情報の整備
・有料情報や独自ノウハウの保護
・アクセスログの監視
・AI検索での自社表示の確認
・引用や要約のされ方のチェック
・利用規約へのAI利用方針の記載
・コンテンツの収益化方針の検討
このような管理を行わなければ、自社の情報がどのようにAIに利用されているのか分からないまま、外部環境だけが変化していきます。
Webサイトは、単なる広報媒体ではなく、企業の情報資産です。AI時代には、その情報資産をどう開放し、どう守り、どう活用するかが問われます。
AIクローラーと収益化の新しい関係
AIクローラーの議論は、ブロックするか許可するかだけではありません。
今後は、AI企業とコンテンツ提供者の間で、ライセンス契約や収益分配の仕組みが広がる可能性があります。
すでに海外では、ニュースメディアや出版社とAI企業がコンテンツ利用に関する契約を結ぶ動きが出ています。これは、WebコンテンツがAI時代の重要なデータ資産になっていることを示しています。
企業サイトや専門メディアにとっても、自社コンテンツの価値を再定義する必要があります。
たとえば、独自調査、専門解説、商品データ、FAQ、レビュー、事例、比較情報などは、AIにとって価値のある情報源になり得ます。ただ公開するだけでなく、どの情報を一般公開し、どの情報を限定提供し、どの情報をライセンス化できるのかを検討する余地があります。
特に専門性の高い業界では、AIに正確な情報を提供すること自体が、新しい信頼構築や収益機会につながるかもしれません。
業種別に見るAIクローラー対応の考え方
ニュース・メディアサイト
ニュースサイトや専門メディアでは、AI検索によるゼロクリックの影響を強く受ける可能性があります。
AIが記事の要点を画面上で要約すれば、ユーザーが元記事を訪問しないケースが増えるかもしれません。その結果、広告収益や会員登録への導線に影響が出る可能性があります。
そのため、メディアサイトでは、AIに読ませる範囲と収益化モデルをセットで考える必要があります。見出しや一部情報は公開しつつ、詳細分析や独自データは会員向けにするなど、階層的な情報設計が重要になります。
ECサイト
ECサイトでは、AIエージェントが商品比較や購入支援を行う場面が増える可能性があります。
そのため、商品情報をAIに正しく理解させることは重要です。価格、在庫、サイズ、素材、配送条件、返品条件、レビュー、FAQなどが整理されていれば、AI経由の購買行動に対応しやすくなります。
一方で、商品データや価格情報を無制限に取得されると、競合分析やスクレイピングに悪用されるリスクもあります。ECサイトでは、AIに提供すべき情報と、保護すべきデータの切り分けが欠かせません。
BtoB・SaaSサイト
BtoBやSaaSのサイトでは、AIが見込み客の情報収集を支援する場面が増えると考えられます。
ユーザーは「このサービスの特徴を比較して」「導入事例を要約して」「料金体系を整理して」とAIに依頼するかもしれません。
そのとき、サービス説明、導入事例、FAQ、料金の考え方、セキュリティ情報、サポート体制などが分かりやすく整理されていれば、AIに正しく理解されやすくなります。
BtoBサイトでは、AIに引用されること自体が商談の入口になる可能性があります。ただし、ホワイトペーパーや提案資料、顧客情報などは適切に管理する必要があります。
企業サイトが確認すべき実務チェックリスト
AIクローラー時代のWeb運営では、まず現状把握から始めることが大切です。
確認すべきポイントは次の通りです。
・robots.txtが設置されているか
・主要なAIクローラーへの許可・拒否方針が整理されているか
・学習利用させたくないコンテンツが明確になっているか
・会員限定情報や有料情報が適切に保護されているか
・アクセスログで不自然なクローリングを確認しているか
・利用規約にAI利用や自動取得に関する考え方が記載されているか
・AI検索で自社名や商品名がどのように表示されるか確認しているか
・FAQや会社情報がAIに理解されやすい形で整理されているか
・構造化データやページ構成が適切か
・AI時代のコンテンツ収益化方針を検討しているか
特に中小企業の場合、最初から高度な対策をすべて行う必要はありません。まずは、自社サイトの情報を「公開してよい情報」「AIに読ませたい情報」「制限すべき情報」に分けるだけでも大きな一歩です。
SEOからAEO、そしてWebガバナンスへ
これまで企業サイトの集客では、SEOが中心的な役割を担ってきました。
しかし、AI検索が普及すると、検索順位だけでなく、AIにどう理解されるか、AIの回答にどう引用されるかが重要になります。これはAEO、つまりAnswer Engine Optimizationの考え方につながります。
ただし、AEOだけでは不十分です。
AIに引用されるためには情報を開く必要があります。一方で、すべてを開けば、自社のコンテンツ価値が失われる可能性もあります。
だからこそ、これからはSEO、AEO、Webガバナンスを一体で考える必要があります。
検索エンジンに見つけてもらうためのSEO。AIに正しく理解されるためのAEO。そして、AIにどこまで利用を許可するかを管理するWebガバナンス。この3つを組み合わせることが、AI時代のWeb運営の基本になります。
まとめ
AIクローラーの進化により、Webサイト運営は新しい段階に入っています。
これからのWebサイトは、人間の読者だけでなく、AIにも読まれることを前提に設計する必要があります。AIに情報を見つけてもらうことは、企業やサービスの認知拡大につながる可能性があります。一方で、無制限な情報取得は、著作権、収益化、ブランド管理、セキュリティの面でリスクを生む可能性もあります。
大切なのは、AIクローラーを単純に拒絶することではありません。
どの情報を開き、どの情報を守り、どの情報を価値として活用するのか。その判断基準を持つことです。
今後、AI検索やAIエージェントがさらに普及すれば、Webサイトの役割は「検索される場所」から「AIに理解され、選ばれ、参照される情報資産」へと変わっていきます。
企業は、SEOだけでなく、AEOとWebガバナンスを組み合わせた運営体制を整える必要があります。
AIクローラー時代のWeb戦略は、まだ始まったばかりです。だからこそ今のうちに、自社サイトの情報設計、公開範囲、制御方法、収益化の可能性を見直しておくことが重要です。
















コメント