

生成AI時代にE-E-A-Tと著作権管理が切り離せなくなった理由
生成AIの普及によって、企業のコンテンツ運用は大きな転換点を迎えています。従来のSEOでは、検索エンジンに評価されるために、専門性のある記事、わかりやすい構成、適切なキーワード設計が重視されてきました。しかし、AI検索やRAG型の情報取得が広がるにつれ、単に「良い記事を書く」だけでは不十分になりつつあります。
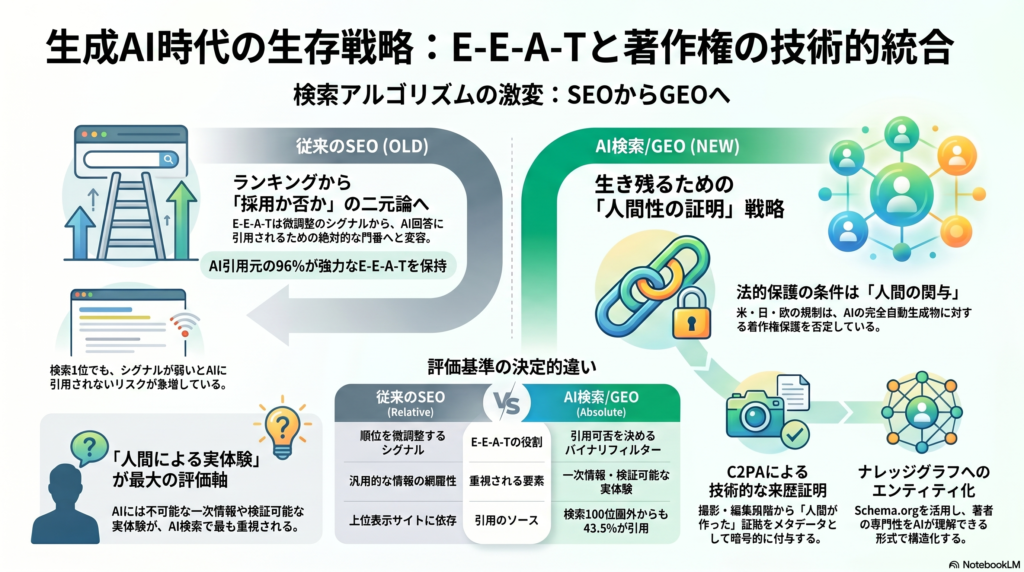
これから重要になるのは、その情報が誰によって作られたのか、どのような根拠に基づいているのか、画像や文章の権利関係は整理されているのか、AIが関与した場合に人間の編集責任がどこにあるのかを説明できる状態です。元資料でも、生成AI時代のE-E-A-Tは、検索順位を上げるための抽象的な評価概念ではなく、AIに引用・参照されるための「信頼の証明」に近づいていると整理されています。
Googleは、AI生成コンテンツそのものを一律に否定しているわけではありません。重要なのは、検索順位の操作を目的とした量産コンテンツではなく、人の役に立つ、信頼できる、読者本位のコンテンツであるかどうかです。Googleの説明でも、Helpful Contentの考え方やE-E-A-Tは、検索評価を理解するための重要な視点として示されています。
E-E-A-Tは「人間らしさ」ではなく「説明可能な信頼性」へ変わる
E-E-A-Tは、Experience、Expertise、Authoritativeness、Trustworthinessの頭文字です。日本語では、経験、専門性、権威性、信頼性と訳されます。以前は、著者プロフィールを整える、専門家監修を入れる、外部リンクを獲得する、といったSEO施策として語られることが多くありました。
しかし、生成AI時代には、E-E-A-Tの意味がより実務的になります。なぜなら、AIは文章の自然さだけでなく、情報の出所、著者の実在性、組織の信頼性、引用可能性、更新履歴、構造化データなどをもとに、参照しやすい情報かどうかを判断する方向に進んでいるからです。
ここで注意したいのは、E-E-A-Tは単独の「ランキング要因」として機械的に足し算されるものではないという点です。Googleの品質評価ガイドラインは、検索品質を評価するための考え方を示すものであり、直接そのまま順位を決める仕組みではありません。ただし、サイト運営者が「どのような情報が信頼されやすいのか」を理解するうえでは、非常に重要な手がかりになります。
つまり、これからのE-E-A-T対策は、見た目だけの著者情報では足りません。誰が書いたのか、なぜその人や企業が語る資格を持つのか、どの資料に基づいているのか、AIを使った場合に最終判断を誰が行ったのかまで、説明できる運用が必要です。
著作権管理はSEOの周辺業務ではなく、信頼性の中核になる
生成AI時代のコンテンツ制作では、著作権管理がE-E-A-Tの中心に入ってきます。理由は明確です。AIを使って文章や画像を作る場合、その成果物にどの程度の人間の創作性があるのか、学習元や参照元に権利上の問題がないのか、第三者素材を無断で使っていないかが問われるからです。
米国著作権局は、生成AIと著作権に関する報告書の中で、AIによって作られた成果物の著作権保護について、人間の創作的関与が重要であるという立場を示しています。単にプロンプトを入力しただけの出力物については、保護の対象として認められにくい一方、人間による創作的な選択、配置、編集、表現上の工夫がある場合には、保護の可能性が検討されます。
これは企業サイトにとっても無関係ではありません。たとえば、AIで作成した記事をそのまま公開した場合、その記事の責任主体は誰なのか、どの部分が人間の判断によるものなのかが曖昧になります。一方、企画、構成、事実確認、専門的な補足、編集、校正、公開判断を人間が行い、そのプロセスを管理していれば、コンテンツの信頼性は高めやすくなります。
EUのAI Actでも、汎用AIモデルに対する透明性や著作権に関する義務が重視されています。特にGPAI、つまり汎用AIモデルの提供者には、技術文書、利用方法、著作権対応、学習データ概要の公表などが関係してきます。
この流れを見ると、企業のコンテンツ運用においても、著作権管理は法務部門だけの仕事ではありません。SEO、広報、マーケティング、制作、情報システム、経営管理が連携し、「どの素材を、どの権利条件で、どのように使ったのか」を残すことが必要になります。
AI検索に引用されるために必要な「出典の見える化」
AI検索やRAG型の回答生成では、情報が断片的に抽出され、要約され、回答の一部として利用されます。このとき、情報の出所が不明確なページ、著者が不明なページ、根拠が弱いページは、引用対象として選ばれにくくなる可能性があります。
重要なのは、AIが理解しやすい形で情報を整理することです。たとえば、記事内で根拠となる資料を明示する、専門家や担当者のプロフィールを設ける、法人情報や問い合わせ先を整備する、公開日と更新日を明確にする、構造化データで著者や組織を示す、といった基本が欠かせません。
GoogleのArticle構造化データでは、著者情報についてPersonやOrganizationを明示し、著者ページのURLやsameAsプロパティを使って本人性・組織性を補強することが推奨されています。Schema.orgでも、sameAsは対象を明確に識別する参照URLとして定義されています。
これは、単なるマークアップ作業ではありません。AIに対して「この記事は誰が責任を持っているのか」「この組織は実在するのか」「この著者は何者なのか」を説明するための土台です。とくにBtoB企業、自治体、士業、医療、介護、金融、建設、教育など、専門性や安全性が重視される分野では、この出典の見える化が大きな差になります。
C2PAとContent Credentialsが示すコンテンツ証明の方向性
文章だけでなく、画像や動画についても、出所の証明が重要になっています。生成AIによる画像、加工画像、合成動画が増えるほど、見る側は「これは本物なのか」「AIで作られたものなのか」「どのように編集されたのか」を判断しづらくなります。
そこで注目されているのが、C2PAやContent Credentialsのようなコンテンツ来歴証明の仕組みです。C2PAは、デジタルコンテンツの出所や編集履歴を証明するための技術標準を開発している団体であり、Content Credentialsは、コンテンツの制作・編集の履歴を確認しやすくする仕組みとして説明されています。
また、Google DeepMindのSynthIDは、AI生成コンテンツを識別するための透かし技術として紹介されています。画像や音声、動画などのAI生成物が増えるなかで、こうしたウォーターマークやメタデータの活用は、今後さらに重要になる可能性があります。
企業サイトで現時点からできることは、完璧な技術導入だけではありません。まずは、画像の作成者、撮影者、生成AIの利用有無、編集日、使用許諾、素材購入元、社内承認者を記録することです。特にアイキャッチ画像、導入事例写真、商品画像、人物写真、図解資料は、権利関係を整理しておく必要があります。
企業サイトが整えるべき実務フロー
1. 著者・監修者・編集責任者を分けて明記する
企業コンテンツでは、記事を書いた人、専門的に確認した人、公開責任を持つ組織が異なることがあります。その場合は、すべてを「スタッフ一同」のように曖昧にせず、役割を分けて明記することが大切です。
たとえば、執筆担当、専門監修、編集責任、最終更新者を分けて管理します。外部ライターを使う場合も、企業側がどの範囲を確認したのかを残しておくべきです。これにより、読者にもAIにも、コンテンツの責任構造が伝わりやすくなります。
2. AI利用の範囲を社内ルール化する
生成AIを使うこと自体は問題ではありません。問題は、どこに使ったのか、どの情報を入力したのか、出力を誰が確認したのかが不明なまま公開されることです。
社内では、AIに入力してよい情報、入力してはいけない情報、AI出力をそのまま公開してはいけない領域、専門家確認が必要な領域を決めておく必要があります。特に、個人情報、未公開情報、顧客情報、契約情報、著作権で保護された資料を安易にAIへ入力する運用は避けるべきです。
3. 参考資料と引用ルールを明確にする
AIを使うと、もっともらしい文章が簡単に作れます。しかし、根拠がない文章は、E-E-A-Tを高めるどころか信頼を損ないます。記事内で統計、制度、法律、技術仕様、行政資料、業界動向に触れる場合は、必ず一次情報や信頼できる資料にあたるべきです。
また、引用と要約の区別も重要です。長い文章をそのまま転載するのではなく、必要な範囲で引用し、出典を明示し、自社の解釈や実務上の示唆を加えることが求められます。
4. 構造化データで人・組織・記事を結びつける
記事ページにはArticle、Organization、Person、BreadcrumbListなどの構造化データを適切に設定します。著者ページ、会社概要、専門家プロフィール、問い合わせページ、実績ページを内部リンクで結び、サイト全体で一貫した情報構造を作ることが大切です。
単発の記事だけを整えても、サイト全体の信頼性は高まりません。誰が、どの領域で、どのような経験を持ち、どの情報に責任を持っているのかを、サイト全体で説明する必要があります。
5. 画像・図解・動画の権利情報を管理する
AI時代の著作権管理では、文章だけでなくビジュアル素材の管理が欠かせません。アイキャッチ画像、図解、インフォグラフィック、写真、動画は、SEOやSNS拡散に大きく影響します。一方で、権利関係が曖昧な素材を使うと、信頼性と法的安全性の両方を損ないます。
最低限、素材の作成方法、作成者、利用ツール、ライセンス、加工履歴、使用範囲、公開日を記録しておきたいところです。将来的にC2PAやContent Credentialsのような仕組みが一般化すれば、こうした記録はより実務上の価値を持つはずです。
やってはいけないE-E-A-T対策
生成AI時代に避けるべきなのは、見せかけの信頼性を作ることです。たとえば、実在しない著者プロフィールを作る、AIで作った専門家コメントを載せる、出典を確認せずに統計らしい数字を入れる、他社記事を要約しただけの記事を大量公開する、といった方法は危険です。
一時的に記事数を増やすことはできるかもしれません。しかし、読者が読んだときに独自の経験や判断がない記事は、企業の信頼資産にはなりません。さらに、AI検索が情報の根拠や引用可能性を重視する方向に進めば、薄い量産記事は参照されにくくなる可能性があります。
E-E-A-Tを高める近道は、派手なテクニックではありません。自社が実際に経験していること、顧客からよく聞く課題、社内に蓄積された知見、現場で検証した内容を、根拠とともに整理することです。生成AIは、その整理や構成、表現の補助として使うべきであり、責任ある判断の代替にはなりません。
まとめ:AIに選ばれるコンテンツは「責任の所在」が明確である
生成AI時代のE-E-A-Tは、従来のSEO施策よりも広い意味を持ちます。経験や専門性を示すだけでなく、誰が作ったのか、何を根拠にしているのか、AIをどのように使ったのか、著作権や素材管理が適切かを説明できることが重要です。
企業サイトにとって、これからのコンテンツ戦略は「記事を増やすこと」ではなく、「信頼され、引用され、長く残る情報資産を作ること」へ移ります。そのためには、著者情報、監修体制、出典管理、構造化データ、画像の来歴管理、AI利用ルールを一体で整える必要があります。
AI検索の時代に評価されるのは、人間の判断が見えるコンテンツです。生成AIを活用しながらも、最終的な責任を人間と組織が引き受ける。その姿勢こそが、これからのE-E-A-Tと著作権管理の核心です。
















コメント