

製造業で暗黙知のデータベース化が求められる理由
製造業の現場には、図面や作業標準書だけでは表現しきれない知識が多く存在します。たとえば、設備の微妙な異音、材料の手触り、加工時の違和感、季節や湿度による調整感覚などです。
これらは、長年現場に立ってきたベテラン技術者が経験の中で身につけた判断力であり、いわゆる「暗黙知」と呼ばれるものです。
しかし、ベテラン技術者の退職や人材不足が進む中で、こうした知識が個人の頭の中に残されたままでは、現場力の低下につながる可能性があります。若手に引き継ごうとしても、「見て覚える」「何度も経験する」という方法だけでは時間がかかり、属人的な技術継承になりやすい点も課題です。
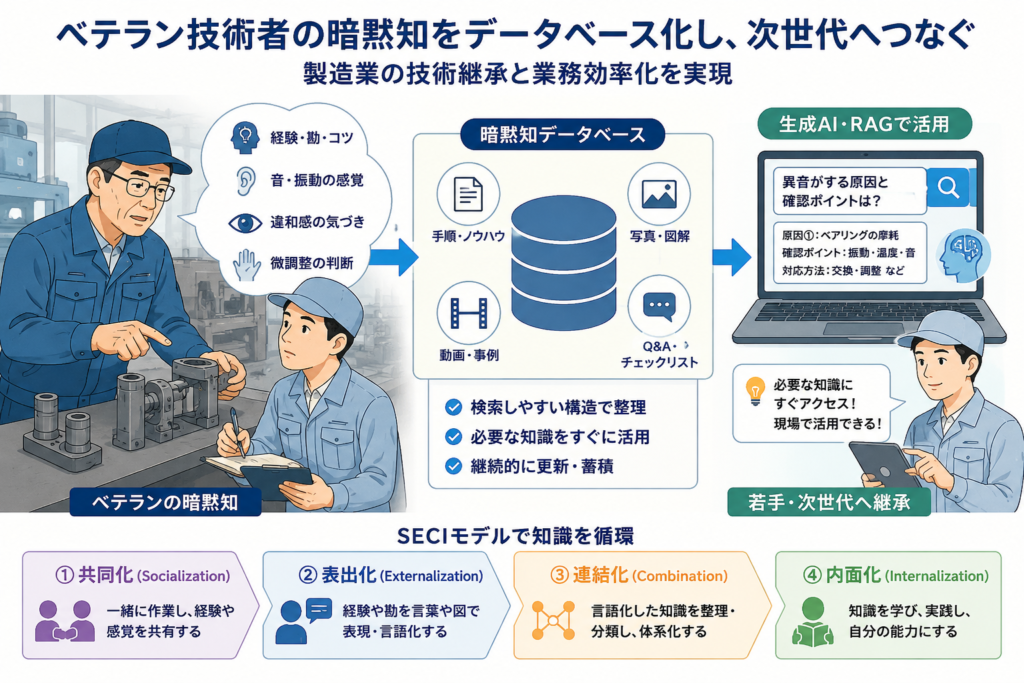
そこで重要になるのが、暗黙知をできる限り言語化し、写真・動画・手順・判断基準と結びつけながらデータベース化する取り組みです。アップロード資料でも、SECIモデル、パターン・ランゲージ、RAG活用、補助金活用を含む実務展開が整理されています。
暗黙知とは何か|マニュアル化しにくい現場ノウハウ
暗黙知とは、本人は自然にできているものの、言葉で説明しにくい知識のことです。
製造業では、次のような知識が暗黙知になりやすい傾向があります。
- 設備の異常を音や振動で判断する感覚
- 加工条件を現場の状態に応じて微調整する判断
- 不良品が出る前兆を見抜く経験則
- 図面には書かれていない組み付けのコツ
- 顧客要求に対する現場判断の勘所
- トラブル発生時の優先順位づけ
これらは単なる「作業手順」ではありません。状況を見て、原因を推測し、最も現実的な対応を選ぶための判断知です。
そのため、暗黙知のデータベース化では、作業を文章にするだけでは不十分です。「どのような状況で」「何を見て」「なぜその判断をしたのか」まで掘り下げる必要があります。
SECIモデルで考える暗黙知の形式知化
暗黙知を整理する考え方として有効なのが、SECIモデルです。SECIモデルでは、知識が次の4つのプロセスを通じて組織内に広がると考えます。
共同化|一緒に作業して感覚を共有する
共同化は、ベテランと若手が同じ現場に入り、作業や判断の感覚を共有する段階です。
たとえば、設備の立ち上げ時に「この音なら問題ない」「この振動は少し注意した方がよい」といった感覚を、実際の現場で一緒に確認します。
ここでは、言葉だけでなく、音・温度・動き・匂い・手触りなど、五感に近い情報が重要になります。
表出化|経験や勘を言葉にする
表出化は、ベテランの頭の中にある判断基準を言語化する段階です。
「なぜその設定にしたのか」「どの状態を見て異常と判断したのか」「過去に似たトラブルはあったのか」といった問いを通じて、経験則を引き出します。
この段階では、単なるインタビューではなく、実際の作業場面を見ながら質問することが効果的です。
連結化|言語化した知識を整理する
連結化は、言語化された知識を分類し、検索しやすい形に整える段階です。
たとえば、「設備別」「工程別」「不具合の種類別」「原因別」「対応策別」「注意点別」に整理することで、必要なときに探しやすくなります。
この工程を飛ばしてしまうと、せっかく集めた知識が単なるメモや議事録の山になり、現場で使われなくなります。
内面化|若手が実務で使える知識にする
内面化は、整理された知識を若手や中堅社員が実際の業務で使い、自分の判断力として身につける段階です。
データベースを読むだけでは、現場力は高まりません。実際のトラブル対応、OJT、社内勉強会、シミュレーション訓練などと組み合わせることで、知識が実践に変わっていきます。
暗黙知データベース化の実務手順
ステップ1|対象となる技術・業務を絞る
最初に行うべきことは、すべての知識を一気に集めようとしないことです。
暗黙知のデータベース化は、範囲を広げすぎると途中で止まりやすくなります。まずは、次のような領域から優先順位をつけると実務に落とし込みやすくなります。
- 不良や手戻りが発生しやすい工程
- ベテランしか判断できない作業
- 退職予定者が持っている重要ノウハウ
- 若手教育に時間がかかっている業務
- 顧客対応や品質判断に直結する知識
「重要だが属人化している業務」から始めるのが現実的です。
ステップ2|ベテラン技術者への聞き取りを設計する
暗黙知を引き出すには、聞き方が重要です。
「コツを教えてください」と聞いても、ベテラン本人は当たり前にやっているため、うまく説明できないことがあります。そのため、具体的な場面に沿って質問する必要があります。
たとえば、次のような質問が有効です。
「この作業で失敗しやすいのはどこですか」
「新人が見落としやすいポイントは何ですか」
「異常に気づくとき、最初にどこを見ていますか」
「過去に大きなトラブルになった事例はありますか」
「その判断をするとき、何と何を比べていますか」
聞き取りは、会議室だけで行うよりも、実際の現場で作業を見ながら行う方が具体的になります。可能であれば、写真や動画も同時に記録します。
ステップ3|パターン・ランゲージで知識を構造化する
聞き取った内容は、そのまま文章にするだけでは活用しづらくなります。そこで有効なのが、パターン・ランゲージの考え方です。
パターン・ランゲージでは、知識を一定の型で整理します。
たとえば、次のような項目です。
- 名称:どのようなノウハウか
- 状況:どんな場面で使う知識か
- 問題:何が起きやすいのか
- 原因:なぜその問題が発生するのか
- 解決策:どのように対応するのか
- 結果:対応すると何が改善されるのか
- 注意点:判断を誤らないための補足
この型を使うことで、個人の経験談が、他の社員にも理解しやすい知識へ変わります。
ステップ4|検索しやすいデータベースにする
暗黙知をデータベース化する際に重要なのは、「蓄積すること」ではなく「探して使えること」です。
そのためには、分類とタグ設計が欠かせません。
たとえば、次のようなタグを設計します。
- 工程名
- 設備名
- 製品カテゴリ
- 不具合名
- 原因
- 対応方法
- 品質基準
- 安全上の注意
- 関連する写真・動画
- 更新日
- 確認者
こうした情報を付けておくことで、「設備名+異音」「工程名+不良」「材料名+温度変化」のように検索しやすくなります。
Excelやスプレッドシートから始めても構いませんが、将来的に生成AIやRAGと連携する場合は、文書の構造やファイル管理ルールも意識しておく必要があります。
生成AI・RAGと暗黙知データベースの相性
暗黙知を整理したデータベースは、生成AIやRAGと組み合わせることで、さらに活用しやすくなります。
RAGとは、社内文書やデータベースを参照しながらAIが回答する仕組みです。通常の生成AIだけに質問すると、事実と異なる回答が出る可能性があります。一方で、RAGを使えば、社内で整理した手順書、トラブル事例、FAQ、技術メモなどを参照しながら回答させることができます。
たとえば、現場担当者が次のように質問できます。
「この設備で異音が出た場合、過去にどんな原因がありましたか」
「この不良が発生したとき、最初に確認すべき項目は何ですか」
「新人にこの作業を教えるときの注意点をまとめてください」
このように、データベースと生成AIを組み合わせることで、知識を探す負担を減らし、現場で使いやすい形に変換できます。
ただし、AIに任せきりにしてはいけません。回答の根拠となる文書を表示する、重要判断は人が確認する、機密情報の取り扱いルールを決める、といった運用設計が必要です。
暗黙知データベース化で失敗しやすいポイント
暗黙知のデータベース化は、進め方を誤ると形だけの取り組みになります。
特に注意すべきなのは、次のようなケースです。
情報を集めるだけで終わる
インタビューや動画撮影をしても、整理されなければ現場では使われません。集めた情報を分類し、検索できる状態にすることが重要です。
ベテランの協力を得られない
ベテラン技術者にとって、自分の知識を言語化することは簡単ではありません。また、「自分の仕事が奪われるのではないか」と感じる場合もあります。
そのため、「技術を残すことが会社と若手のためになる」「本人の貢献を見える化する」という伝え方が大切です。
若手教育とつながっていない
データベースを作っても、若手が使わなければ意味がありません。OJT、研修、朝礼、改善活動、トラブル共有会などと結びつける必要があります。
更新ルールがない
現場の知識は一度作れば終わりではありません。設備更新、材料変更、顧客要求の変化によって、判断基準も変わります。
更新担当者、確認者、見直し頻度を決めておくことが重要です。
導入時に見るべき効果指標
暗黙知データベース化の効果は、単に登録件数だけで判断すべきではありません。重要なのは、現場の業務改善につながっているかどうかです。
たとえば、次のような指標が考えられます。
- 若手が一人で対応できる作業範囲
- トラブル対応にかかる時間
- 同じ不具合の再発件数
- 教育に必要な期間
- ベテランへの問い合わせ件数
- 作業標準書やFAQの利用回数
- 現場からの改善提案件数
数値化できるものだけでなく、「判断に迷う時間が減った」「新人教育がしやすくなった」といった定性的な変化も重要です。
補助金や外部支援を活用する考え方
暗黙知のデータベース化には、聞き取り、動画撮影、文書整理、システム構築、AI連携などの作業が発生します。社内だけで進めるのが難しい場合は、外部支援や補助金の活用も検討できます。
特に、ITツール導入、業務改善、DX推進、人材育成に関連する支援制度は、取り組み内容によって活用できる可能性があります。
ただし、補助金は年度や公募回によって要件が変わります。実際に活用する場合は、最新の公募要領を確認し、対象経費や申請条件を整理したうえで進める必要があります。
重要なのは、「補助金があるからシステムを入れる」のではなく、「現場の知識継承課題を解決するために、必要な仕組みを整える」という順番です。
まとめ|暗黙知のデータベース化は現場力を未来へ残す取り組み
製造業における暗黙知のデータベース化は、単なるデジタル化ではありません。ベテラン技術者が長年かけて培ってきた判断力や経験を、次世代へ引き継ぐための経営課題です。
成功のポイントは、最初から大きなシステムを作ろうとしないことです。まずは、重要工程や属人化している業務を絞り、現場で使える知識を一つずつ整理することが現実的です。
そのうえで、SECIモデルを意識しながら、共同化、表出化、連結化、内面化の流れを作ります。さらに、RAGや生成AIと連携できる形に整えていけば、暗黙知は単なる記録ではなく、現場で使える知識資産になります。
人手不足や技術継承の課題が続く中で、ベテランの知恵を会社全体の資産に変えることは、製造業の競争力を守るための重要な一歩です。
















コメント