

自治体の生成AI活用は「庁内FAQ・RAG整備」が土台になる
自治体における生成AI活用は、単なるチャットボット導入の段階から、庁内業務の知識をどう整理し、どう安全に参照させるかという段階へ移りつつあります。デジタル庁でも、行政実務を支援する生成AI利用環境「源内」を内製開発し、国会答弁検索AIや法制度調査支援AIなど複数のアプリケーションを提供して検証を進めています。2025年5月から7月までの3か月間で、デジタル庁職員約1,200人のうち約950人が利用し、利用回数は延べ6万5,000回以上に達したとされています。
一方で、自治体が同じように生成AIを活用しようとすると、必ずぶつかるのが「庁内データの整備不足」です。規程、通知、マニュアル、FAQ、議事録、過去の照会回答、住民対応記録などは存在していても、形式や保存場所、更新頻度、責任部署がばらばらであることが少なくありません。RAGは、こうした庁内文書をAIが参照できるようにする仕組みですが、元データが整理されていなければ、回答精度は安定しません。アップロード資料でも、FAQ・RAG整備はモデル選定だけでなく、データガバナンス、LGWAN環境、チャンク設計、KPI評価、継続改善を含む実務プロセスとして整理されています。
庁内FAQとRAGの違いを整理する
庁内FAQは、職員がよく使う質問と回答を整理した知識ベースです。人事、契約、財務、文書管理、情報セキュリティ、住民対応など、部署横断で繰り返される問い合わせを標準化する役割があります。
一方、RAGは「検索拡張生成」と呼ばれる仕組みで、生成AIが回答を作る前に、指定された文書群から関連情報を検索し、その内容を根拠として回答を生成します。つまり、FAQは「整理された知識そのもの」であり、RAGは「その知識をAIが使いやすくする仕組み」です。
自治体で重要なのは、いきなりRAGを構築することではありません。まず庁内FAQや業務文書を整理し、どの情報をAIに参照させてよいかを決めることです。ここを飛ばすと、古い規程を参照した回答、根拠の薄い回答、担当部署によって解釈が異なる回答が出る可能性があります。
最初に決めるべきはAIガバナンスと役割分担
庁内FAQ・RAG整備では、情報システム部門だけに責任を寄せると失敗しやすくなります。AI事業者ガイドライン第1.1版では、AIに関わる主体をAI開発者、AI提供者、AI利用者に分け、人間中心、安全性、公平性、プライバシー保護、セキュリティ確保、透明性、アカウンタビリティなどの共通指針を整理しています。
自治体に置き換えると、情報政策部門は基盤やルールを設計し、各業務主管課は参照させる文書の正確性を担保し、法務・情報公開・個人情報保護の担当部署はリスク判断を行う体制が必要です。さらに、職員はAIの回答をそのまま行政判断に使うのではなく、根拠文書を確認したうえで業務に反映する役割を持ちます。
特に重要なのは、導入前に「誰がデータを登録するのか」「誰が古い情報を削除するのか」「回答ミスが発生した場合に誰が修正するのか」を決めておくことです。RAGは導入して終わりではなく、運用しながら育てる庁内基盤です。
データ分類でAIに読ませる情報を決める
自治体の庁内データには、公開資料から個人情報、要配慮情報、契約情報、政策形成過程の情報までさまざまなレベルがあります。そのため、FAQ・RAG整備では、まず情報を分類する必要があります。
実務上は、公開済み情報、庁内限定情報、個人情報を含む情報、機密性の高い政策・契約情報のように段階を分けると整理しやすくなります。公開資料や一般的な手続きマニュアルはRAGに組み込みやすい一方で、住民個人に関する相談記録や未公開の政策資料は慎重に扱うべきです。
ここで大切なのは、「便利だから全部入れる」という発想を避けることです。AIに参照させるデータは、業務上の有用性だけでなく、情報公開、個人情報保護、セキュリティ、委託契約上の制約を踏まえて選ぶ必要があります。
LGWAN環境ではシステム構成を現実的に選ぶ
自治体では、LGWAN環境とインターネット接続環境の分離が大きな制約になります。デジタル庁の地方公共団体との検証でも、LGWAN上で生成AIを利用する場合、Web検索機能や外部資料の読み込みに制限があるため、それらを前提にしないプロンプト運用が必要だったと整理されています。
このため、庁内FAQ・RAGの構成には大きく二つの方向があります。ひとつは、LGWAN-ASPなど閉域網側で完結する構成です。安全性を重視しやすい一方で、利用できるモデルや外部連携に制約が出る可能性があります。もうひとつは、インターネット分離環境でAIサービスを活用し、ファイルの無害化やデータ持ち出し制御を組み合わせる構成です。柔軟性は高いものの、セキュリティ設計と運用ルールがより重要になります。
どちらが優れているかではなく、自団体の情報分類、業務範囲、職員の利用環境、既存システムとの接続条件に合わせて選ぶことが現実的です。
RAG精度を左右するデータ前処理
RAGの回答精度は、AIモデルだけで決まりません。むしろ、登録する文書の品質によって大きく変わります。古いマニュアル、重複したFAQ、表記ゆれの多い文書、タイトルだけでは内容が分からないPDFが混在していると、AIは正しい情報を探しにくくなります。
まず行うべきは、重複データの削除です。同じ内容の通知やFAQが複数存在すると、AIはどれを優先すべきか判断しにくくなります。次に、古い版と最新版の区別を明確にします。改定日、所管課、対象業務、文書種別などのメタデータを付けることで、検索精度を高めやすくなります。
さらに、PDFやWord文書をそのまま登録するのではなく、見出し構造を整え、質問と回答の単位に分解し、AIが参照しやすい文章へ整形することが重要です。資料のp7では、RAG精度を高める前処理として、重複・短文・冗長データの整理、メタデータ付与、FAQ形式への再構成が実務上のポイントとして示されています。
チャンク設計は「短ければよい」わけではない
RAGでは、文書を一定の単位に分割して検索対象にします。この分割単位をチャンクと呼びます。チャンクが短すぎると文脈が失われ、長すぎると検索精度や処理コストに影響します。
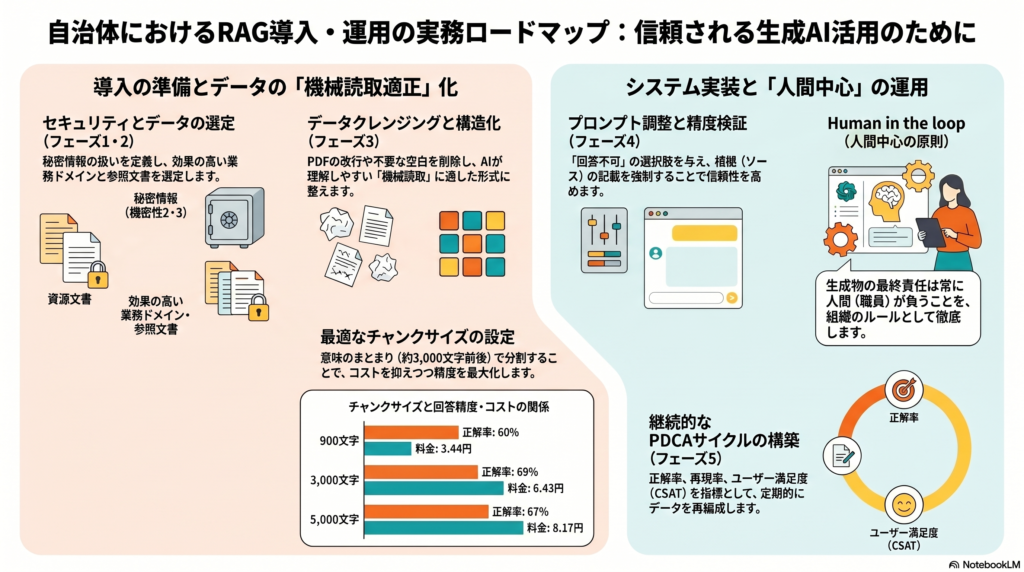
自治体文書では、制度説明、例外規定、手続きフロー、担当部署、根拠規程がセットで意味を持つことが多いため、単純に細かく分ければよいわけではありません。資料のp8では、チャンクサイズとオーバーラップ量を変えた比較表が掲載され、3,000文字前後のチャンクが一例として比較的高い正答率を示しています。ただし、これはあくまで検証条件に基づく結果であり、すべての自治体文書にそのまま適用できる万能値ではありません。
実務では、人事FAQ、契約規則、議会答弁、住民向け手続き案内など、文書の種類ごとに適切な分割単位を検証する必要があります。
プロンプト設計では「回答しない条件」も決める
RAGのプロンプトでは、回答の形式だけでなく、回答してはいけない条件を明確にすることが重要です。たとえば、根拠文書に記載がない場合は「確認できません」と答える、複数の解釈がある場合は担当課確認を促す、個人情報や政策判断を含む場合はAI単独で結論を出さない、といったルールです。
また、回答には参照元の文書名、更新日、該当箇所を示す設計が望まれます。職員が最終確認できる形にしなければ、AIの回答は業務上の根拠として使いにくくなります。
資料のp9でも、回答選択時の制約、引用・根拠提示、自己検証のプロンプト、Human in the loopの重要性が整理されています。生成AIの回答を「便利な下書き」として使いつつ、最終判断は人が担う設計にすることが、自治体業務では欠かせません。
PoCではKPIを決めて検証する
庁内FAQ・RAGのPoCでは、「なんとなく便利だった」で終わらせてはいけません。導入判断につなげるには、事前にKPIを決める必要があります。
代表的な指標は、正答率、再現率、利用満足度です。正答率は、AIの回答が根拠文書に照らして正しいかを確認する指標です。再現率は、必要な情報をどれだけ拾えているかを測る指標です。利用満足度は、職員が実務で使いやすいと感じるかを確認します。
加えて、問い合わせ削減件数、回答作成時間の短縮、担当課への確認回数、誤回答の発生傾向なども見ると、業務改善との接続がしやすくなります。資料のp10では、PoCにおける評価指標として、正答率、再現率、CSATを中心に整理されています。
庁内FAQ・RAG整備の5段階ロードマップ
フェーズ1:ガバナンスとセキュリティルールを決める
最初に、AI利用ルール、情報分類、禁止事項、利用対象業務、責任部署を決めます。特に、個人情報や機密情報をどのように扱うかを明文化することが重要です。
フェーズ2:対象業務と文書を選ぶ
次に、問い合わせが多い業務、属人化している業務、マニュアル参照が多い業務を洗い出します。最初から全庁展開を狙うより、人事、総務、契約、情報システムなど、効果を測りやすい領域から始める方が現実的です。
フェーズ3:データクレンジングとメタデータ整備を行う
登録する文書を整理し、最新版管理、重複削除、見出し構造の整理、所管課や更新日の付与を行います。この段階が弱いと、RAGの精度は安定しません。
フェーズ4:システム統合とPoCを実施する
LGWAN環境、インターネット分離環境、既存の文書管理システムとの連携を踏まえ、PoCを行います。回答精度だけでなく、職員が日常業務で使える導線になっているかも確認します。
フェーズ5:全庁展開とPDCA運用へ移行する
PoCで得たログやフィードバックをもとに、FAQを更新し、プロンプトを改善し、対象業務を広げます。資料のp13〜p14でも、ガバナンス整備から文書選定、データ整備、システム統合、全庁展開・PDCA運用へ進む段階的手順が示されています。
まとめ:自治体RAGは「AI導入」ではなく「知識基盤整備」である
庁内FAQ・RAG整備の本質は、生成AIを導入することではありません。自治体の中に散在する知識を整理し、安全に使える形へ変換し、職員が根拠を確認しながら活用できる業務基盤をつくることです。
そのためには、AIモデルの性能だけでなく、情報分類、LGWAN対応、データ前処理、チャンク設計、プロンプト設計、KPI評価、継続的なFAQ更新までを一体で考える必要があります。生成AIは、整ったデータと明確な運用ルールがあって初めて、自治体業務の省力化や品質向上に結びつきます。
これからの自治体DXでは、庁内FAQ・RAGは単なる検索支援ではなく、職員の判断を支える「行政知識インフラ」として位置づけることが重要です。
















コメント