
RAGシステムの正確性評価が企業導入で重要になる理由
RAGは、社内文書やナレッジベースを検索し、その内容をもとに生成AIが回答する仕組みです。企業利用では、単に「それらしい回答が出る」だけでは不十分です。回答が社内規程、契約情報、製品仕様、FAQ、業務マニュアルなどに基づいているかを継続的に確認する必要があります。
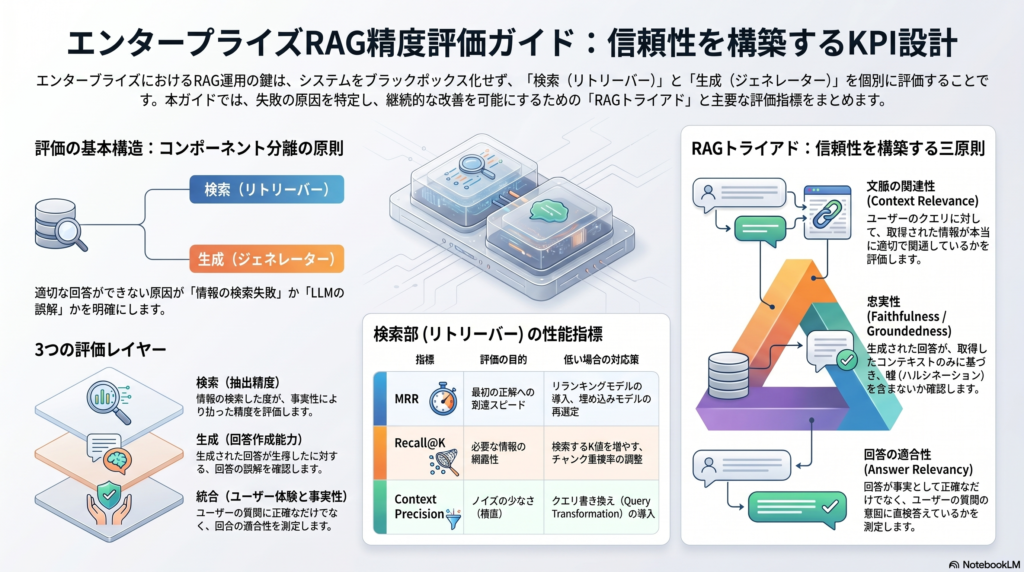
アップロード資料では、RAGの正確性評価を「検索」「生成」「統合」の3層に分けて設計する考え方が示されています。検索で必要な情報を拾えているか、生成回答が根拠に忠実か、最終回答がユーザーの意図に合っているかを分けて見ることで、問題箇所を特定しやすくなります。
RAG評価は「検索・生成・統合」の3層で考える
検索層:必要な文書を正しく取得できているか
RAGの品質は、まず検索品質に左右されます。どれほど高性能なLLMを使っても、参照すべき文書が検索結果に含まれていなければ、回答は不完全になります。
検索層では、MRR、NDCG、Recall@K、Context PrecisionなどのKPIを使い、検索結果の順位、網羅性、ノイズの少なさを確認します。Ragasの公式ドキュメントでも、Context Precisionは取得されたコンテキストが回答に役立つかを評価する指標として説明されています。
生成層:回答が根拠に忠実か
生成層では、LLMが取得文書に基づいて回答しているかを確認します。ここで重要になるのがFaithfulnessやGroundednessです。DeepEvalの公式ドキュメントでは、Faithfulnessは実際の出力が検索されたコンテキストと事実的に整合しているかを測る指標として説明されています。
つまり、RAGの回答では「正しそうに見える」だけでは足りません。参照文書に書かれていない情報を断定していないか、条件や例外を勝手に補っていないかを確認する必要があります。
統合層:最終回答として役に立つか
検索と生成がそれぞれ良好でも、最終回答がユーザーの質問に答えていなければ意味がありません。統合層では、Answer Correctness、Answer Relevancy、User Satisfactionなどを用いて、回答全体の有用性を確認します。
TruLensのRAG Triadでは、context relevance、groundedness、answer relevanceの3要素でRAGアプリケーションの信頼性を見る考え方が示されています。
検索精度を見る主要KPI
MRR:最初の正解がどれだけ上位に出るか
MRRは、正しい文書が検索結果の何番目に出てくるかを見る指標です。ユーザーの質問に対して、必要な文書が1位や2位に表示されるほど、回答生成に使われやすくなります。
業務用RAGでは、検索結果の上位数件だけをLLMに渡すことが多いため、正解文書が下位に埋もれると、回答の根拠から外れてしまう可能性があります。
NDCG:検索順位全体の妥当性を見る
NDCGは、検索結果全体の順位品質を見る指標です。完全な正解文書だけでなく、関連度の高い文書がどの位置に並んでいるかを確認できます。
たとえば、社内規程、手順書、FAQが混在するRAGでは、最も根拠性の高い文書を上位に置く設計が重要です。関連性はあるが古い文書、補足資料にすぎない文書が上位に来る場合は、検索インデックスやチャンク設計の見直しが必要になります。
Recall@K:必要情報を取り逃がしていないか
Recall@Kは、上位K件の検索結果に必要な情報が含まれているかを見る指標です。特に社内FAQ、規程検索、技術サポートでは、取り逃がしが回答ミスに直結します。
Recallが低い場合は、チャンク分割が細かすぎる、メタデータが不足している、同義語や略語に対応できていない、検索クエリ変換が弱いといった原因が考えられます。
Context Precision:不要な情報が混ざっていないか
検索では、必要な文書を拾うだけでなく、不要な文書を混ぜすぎないことも重要です。Context Precisionが低いと、LLMが不要な情報に引っ張られ、回答がぼやけたり、誤った根拠を使ったりする可能性があります。
RAG評価では「たくさん検索すれば安心」と考えがちですが、情報量を増やすほどノイズも増えます。検索結果の量と精度のバランスを取ることが、実運用では欠かせません。
生成回答の信頼性を見るKPI
Faithfulness:根拠に忠実な回答か
Faithfulnessは、回答内容が取得文書に支えられているかを見る指標です。RAGで最も避けたいのは、根拠文書にない内容をAIが自然な文章で補ってしまうことです。
たとえば、社内規程に「上長承認が必要」としか書かれていないのに、AIが「部長承認が必要です」と断定した場合、文章としては自然でも根拠に忠実とはいえません。企業利用では、このような小さなズレが業務判断の誤りにつながる可能性があります。
Answer Relevancy:質問意図に合っているか
Answer Relevancyは、回答がユーザーの質問意図に合っているかを見る指標です。根拠には忠実でも、質問に直接答えていない回答は実務では使いにくくなります。
たとえば「経費精算の締切はいつか」と聞かれているのに、経費精算制度の概要だけを長く説明する回答は、正確ではあっても有用性が低いと評価されます。RAGでは、根拠性と回答性を分けて評価することが重要です。
LLM-as-a-Judgeを使う場合の注意点
RAG評価では、LLMを評価者として使うLLM-as-a-Judgeが広く使われます。LangSmithの公式チュートリアルでも、RAGアプリケーションに対してテストデータセットを作成し、複数の評価指標で測定する流れが紹介されています。
ただし、LLM-as-a-Judgeには注意点があります。評価するLLM自体にもバイアスや揺らぎがあり、同じ回答でも評価が変わる場合があります。そのため、重要な業務領域では、LLM評価だけに依存せず、人間によるレビューやゴールデンデータセットとの照合を組み合わせるべきです。
特に、法務、医療、金融、人事、行政手続きなどの領域では、回答の自然さよりも、根拠への忠実性、例外条件の扱い、拒否すべき質問への対応を重視する必要があります。
実運用で追加すべきKPI
レイテンシ:業務で待てる速度か
RAGは検索、再ランキング、生成を組み合わせるため、通常のチャットより応答が遅くなることがあります。回答が正確でも、業務中に待ち時間が長すぎれば利用されにくくなります。
そのため、TTFT、End-to-End Latency、P95レイテンシなどを継続的に確認し、利用者がストレスを感じにくい水準を探ることが大切です。
Cost per Query:継続利用できるコストか
RAGは、検索回数、再ランキング、LLMの入力トークン、出力トークンによってコストが変動します。精度向上のために検索件数やコンテキスト量を増やすと、コストも増えやすくなります。
企業導入では、精度だけでなく、1問い合わせあたりのコストを把握し、業務価値に見合う設計にする必要があります。
Refusal Rate:答えるべき質問に答え、拒否すべき質問を拒否できているか
RAGには、答えてはいけない質問を拒否する能力も必要です。機密情報、個人情報、未公開情報、権限外の情報については、正しく拒否する設計が求められます。
一方で、必要以上に拒否が増えると、利用者は使いにくさを感じます。Refusal Rateは、セキュリティと利便性のバランスを見るための重要なKPIです。
ドリフト検知:時間とともに品質が落ちていないか
RAGは一度作って終わりではありません。社内文書が更新され、商品仕様が変わり、FAQが増えれば、検索結果や回答品質も変わります。
Embedding Drift、検索ヒット率の変化、回答根拠の変化、ユーザーからの低評価率などを見ながら、品質低下の兆候を早めに把握する必要があります。
ゴールデンデータセットを整備する
RAG評価で重要なのが、ゴールデンデータセットです。これは、よくある質問、難しい質問、例外的な質問、拒否すべき質問などを集めた評価用データです。
ゴールデンデータセットには、質問、期待される回答、参照すべき根拠文書、許容される表現、禁止すべき回答を含めると運用しやすくなります。特に企業利用では、現場で実際に発生する質問をもとに作ることが重要です。
また、データセットは固定ではなく、問い合わせログや失敗事例をもとに定期的に更新します。これにより、評価が現場の実態からずれることを防げます。
RAG評価の運用フレームワーク
RAGの評価は、開発時だけでなく、運用中も継続する必要があります。まず初期段階では、検索精度、生成の忠実性、回答の関連性を測定します。次に、本番前にはゴールデンデータセットを使って回帰テストを行います。
本番後は、ユーザーフィードバック、低評価ログ、回答の根拠、レイテンシ、コストをモニタリングします。問題が見つかった場合は、検索設定、チャンク設計、プロンプト、再ランキング、ナレッジベースの更新を見直します。
この改善サイクルを回すことで、RAGは単なる検索付きチャットではなく、業務に耐えるナレッジ基盤へ近づきます。
まとめ
RAGシステムの正確性評価では、単一のスコアだけを見るのではなく、検索、生成、統合の3層に分けてKPIを設計することが重要です。
検索層では、MRR、NDCG、Recall@K、Context Precisionによって、必要な情報を正しく取得できているかを確認します。生成層では、FaithfulnessやAnswer Relevancyを使い、根拠に忠実で質問意図に合った回答かを見ます。さらに実運用では、レイテンシ、コスト、拒否率、ドリフト検知を加えることで、企業利用に必要な信頼性を維持しやすくなります。
RAGの品質は、導入時の一度きりの評価では保てません。ゴールデンデータセットを整備し、定期的な評価と改善を続けることが、エンタープライズRAGを安定運用するための現実的な方法です。

















コメント