

はじめに:AI活用は「使う」から「設計・評価する」段階へ
生成AIの活用は、単にチャット画面に質問を入力する段階から、社内文書や業務システムと連携し、より実務に近い判断や作業を支援する段階へ進んでいます。その中心にあるのが、RAGとAIエージェントです。
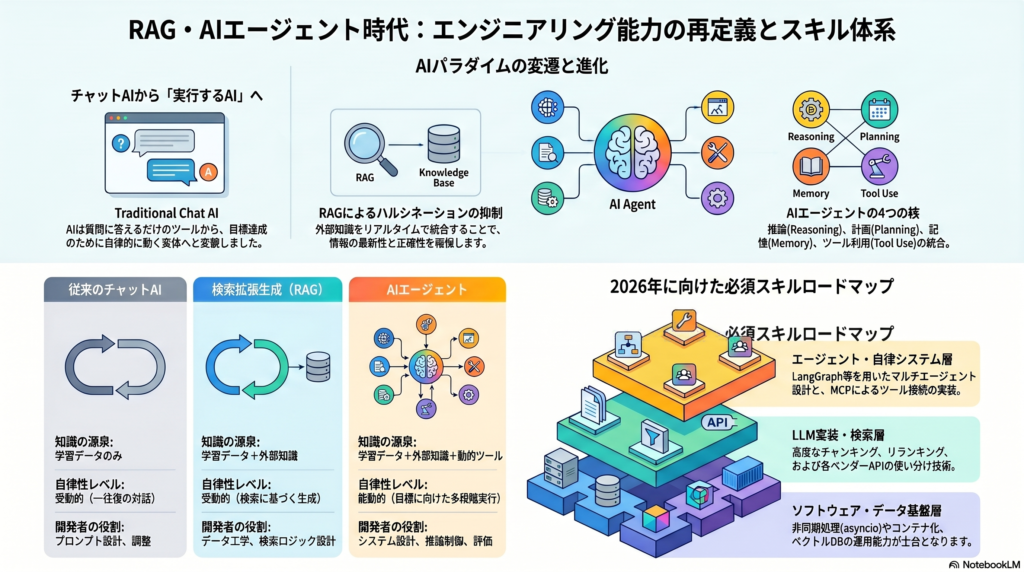
RAGは、社内文書やFAQ、マニュアルなどの外部情報を検索し、その内容をもとに生成AIが回答する仕組みです。一方、AIエージェントは、目標に向かって複数の手順を考え、必要に応じてツールを呼び出しながら作業を進める仕組みです。元資料でも、従来型チャットAI、RAG、AIエージェントの違いが、知識源、自律性、主な課題、開発者の役割という観点で整理されています。
ここで重要になるのは、エンジニアに求められる力が変わってきているという点です。これからは、単にコードを書く力だけでは不十分です。AIに何を参照させるか、どのように判断させるか、どこで人間が確認するか、回答の正確性をどう評価するかまで設計する力が必要になります。
RAG・AIエージェント時代に変わるエンジニアの役割
従来のAI活用では、プロンプトを工夫して回答の質を高めることが重視されてきました。もちろん、プロンプト設計は今後も重要です。しかし、RAGやAIエージェントを業務に導入する場合、プロンプトだけで品質を担保することは難しくなります。
たとえば、社内規程を参照して回答するAIを作る場合、そもそも文書が適切に分割されているか、検索対象が最新か、似た文書が複数ある場合にどれを優先するか、といった設計が必要です。AWSもAdvanced RAGの改善領域として、データ準備、クエリ処理、検索、検索結果の後処理、回答生成を挙げています。つまり、RAGの精度は「AIモデルの性能」だけでなく、周辺の情報設計によって大きく左右されます。
AIエージェントの場合は、さらに複雑です。OpenAIのAgents SDKの説明では、エージェントは計画を立て、ツールを呼び出し、専門エージェント同士で連携し、複数ステップの作業を完了するための状態を保持するアプリケーションとして説明されています。
つまり、エンジニアの役割は「AIに質問する人」ではなく、「AIが安全に動く業務構造を設計する人」へ変わりつつあります。
RAGに必要なエンジニアリング能力
チャンク設計:文書をどう分けるか
RAGの精度を左右する最初のポイントは、文書の分割です。これをチャンク設計と呼びます。
社内文書をそのままAIに渡しても、必要な箇所を正確に参照できるとは限りません。文章を細かく分けすぎれば、文脈が失われます。逆に大きく分けすぎれば、検索結果に不要な情報が混ざりやすくなります。
たとえば、自治体の庁内FAQや企業の業務マニュアルでは、「申請条件」「必要書類」「例外処理」「問い合わせ先」が同じ文書内に含まれていることがあります。これらをどの単位で分けるかによって、AIの回答精度は変わります。エンジニアには、単なるテキスト処理ではなく、業務文書の構造を理解したうえで検索しやすい形に整える力が求められます。
ベクトル検索・ハイブリッド検索・リランキング
RAGでは、ユーザーの質問に近い文書を探すために、ベクトル検索が使われることがあります。ベクトル検索は、言葉の意味的な近さをもとに情報を探す方法です。ただし、業務現場では固有名詞、制度名、製品名、条文番号など、キーワードの一致が重要になる場面も少なくありません。
そのため、意味で探すベクトル検索と、キーワードで探す検索を組み合わせるハイブリッド検索が重要になります。AWSも、専門用語や名称を検索する場面では従来型のキーワード検索が有効であり、セマンティック検索とキーワード検索を組み合わせるハイブリッド検索に触れています。
さらに、検索された候補をそのまま使うのではなく、質問への関連度が高い順に並べ直すリランキングも重要です。Amazon Bedrockのドキュメントでは、リランキングモデルがチャンクとクエリの関連性を計算し、検索結果を並べ替えることで、より適切な応答生成につなげると説明されています。
RAGを業務で使うには、「検索できる」だけでは足りません。必要な情報を、必要な順番で、必要な粒度でAIに渡す設計が必要です。
回答精度を評価する仕組み
RAG導入で見落とされやすいのが、評価設計です。AIがもっともらしい回答をしていても、根拠文書と合っていなければ業務では使えません。
評価では、少なくとも次の観点を確認する必要があります。
- 回答が根拠文書に基づいているか
- 質問に対して必要な情報を含んでいるか
- 不要な推測や言い切りが混ざっていないか
- 検索結果に適切な文書が含まれているか
- 回答の再現性があるか
元資料でも、RAGの信頼性評価として、Faithfulness、Answer Relevancy、Context Precision、Context Recallといった観点が整理されています。
これは、AI導入を「試して終わり」にしないために欠かせない工程です。業務で使うAIほど、評価指標とテストデータを整備し、改善サイクルを回す必要があります。
AIエージェントに必要な設計力
推論ループとタスク分解
AIエージェントは、単発の回答ではなく、目標達成に向けて複数の処理を進めます。たとえば、「会議資料を作成する」という指示に対して、関連資料を探す、要点を抽出する、構成を作る、文章化する、確認点を洗い出す、といった工程を自律的に進める可能性があります。
このとき重要になるのが、タスク分解です。どこまでAIに任せるのか、どの段階で人間が確認するのか、失敗したときにどう戻すのかを設計しなければなりません。
AIエージェント開発では、単に「賢いAIを使う」だけではなく、業務プロセスそのものを分解し、AIに任せる部分と人間が担う部分を整理する力が求められます。
ツール利用・MCP・外部システム連携
AIエージェントが実務で価値を出すには、外部システムとの連携が欠かせません。たとえば、ファイル検索、データベース参照、社内システムの操作、スケジュール確認、メール作成などです。
OpenAIのツールドキュメントでは、Web検索、ファイル検索、関数呼び出し、リモートMCPサーバーなどを使って、モデルの能力を拡張できると説明されています。
また、AnthropicのMCP説明では、MCPはAIアプリケーションを外部システムに接続するためのオープン標準であり、データソース、ツール、ワークフローへの接続を可能にするとされています。
この流れを見ると、今後のエンジニアには、API連携や認証、権限管理、ログ管理、データ連携の設計力がますます重要になります。AIエージェントは、社内システムに接続されて初めて実務効果を発揮する一方、接続範囲を誤れば情報漏えいや誤操作のリスクも高まります。
Human-in-the-Loopとガードレール
AIエージェントを業務に導入する際は、すべてを自動化する発想は危険です。特に、契約、個人情報、行政判断、財務、採用、人事評価などの領域では、人間による確認を組み込む必要があります。
OpenAIのAgents SDKでは、リスクのある処理の前にワークフローを止めたり、人間のレビューを加えたりする場面で、ガードレールや人間の確認を使うことが示されています。
AIエージェントの設計では、「どこまで自動化するか」以上に、「どこで止めるか」が重要です。承認、差し戻し、ログ確認、例外処理を含めて設計することで、現場で安心して使える仕組みに近づきます。
運用で求められるLLMOps・ガバナンス
RAGやAIエージェントは、作って終わりではありません。運用中に文書が更新され、モデルが変わり、利用者の質問傾向も変化します。そのため、継続的な改善と監視が必要です。
具体的には、次のような運用項目が必要になります。
- 回答ログの確認
- 誤回答の分析
- 検索精度の改善
- プロンプトやツール設定の見直し
- 利用権限の管理
- 個人情報・機密情報の扱いの確認
- コスト・レイテンシの監視
- 利用部門への教育
NISTのAI Risk Management Frameworkでは、AIリスク管理において、Govern、Map、Measure、Manageという機能を通じて、信頼できるAIシステムを責任ある形で開発・管理する考え方が示されています。
企業や自治体がAIを導入する場合も、同じ視点が必要です。便利だから導入するのではなく、リスクを把握し、測定し、管理しながら活用する体制が求められます。
2026年に向けたAIエンジニア育成ロードマップ
RAG・AIエージェント時代の人材育成では、段階的なスキル習得が現実的です。いきなり高度なAIエージェントを作ろうとするよりも、まずは基礎技術と評価の考え方を固める必要があります。
第一段階は、Python、API、クラウド、データベース、認証、ログ管理などの基礎です。AI開発といっても、実際には既存システムとの接続やデータ処理が多くを占めます。
第二段階は、RAGの実装です。文書の取り込み、チャンク設計、ベクトル化、検索、リランキング、回答生成、評価までを一通り経験することで、生成AIを業務データと結びつける感覚が身につきます。
第三段階は、AIエージェント設計です。タスク分解、ツール利用、状態管理、外部API連携、Human-in-the-Loopを含むワークフロー設計を学ぶ必要があります。
第四段階は、評価とガバナンスです。AIの回答をどう測るか、誤回答をどう改善するか、個人情報や機密情報をどう守るか、運用ルールをどう作るかまで含めて考える段階です。
この流れを踏むことで、AIを「試す人材」から、AIを「業務に実装し、改善し、管理できる人材」へ育成できます。
企業・自治体が今から準備すべきこと
RAGやAIエージェントを導入する前に、企業や自治体が準備すべきことは明確です。
まず、AIに参照させる情報を整備することです。FAQ、規程、マニュアル、議事録、問い合わせ履歴などが古いままでは、AIの回答も不安定になります。
次に、AIに任せる業務と任せない業務を分けることです。定型的な情報検索や文書案作成はAIに向いています。一方で、最終判断、例外対応、説明責任が重い業務は人間の確認が必要です。
さらに、導入後の評価体制を決めておくことも重要です。誤回答が出たときに誰が確認するのか、文書を更新したときに検索データへどう反映するのか、利用ログをどの範囲で確認するのかを事前に決めておく必要があります。
AI導入は、ツール選定だけでは成功しません。業務、データ、セキュリティ、人材育成を一体で考えることが重要です。
まとめ:AI時代のエンジニアは、設計者であり監督者である
RAG・AIエージェント時代において、エンジニアの役割は大きく変わりつつあります。これまでのように、システムを作るだけではなく、AIが参照する情報、判断する流れ、外部システムとの接続、人間が確認するポイント、評価と改善の仕組みまで設計する必要があります。
RAGでは、チャンク設計、検索設計、リランキング、評価が重要です。AIエージェントでは、タスク分解、ツール連携、状態管理、Human-in-the-Loop、ガードレールが重要です。そして、業務導入では、LLMOpsとガバナンスの視点が欠かせません。
AIは、導入すれば自動的に成果を出すものではありません。成果を出すためには、業務を理解し、データを整え、リスクを管理し、継続的に改善する人材が必要です。
これからのエンジニアリング能力とは、AIに置き換えられない力ではなく、AIを業務の中で正しく働かせる力です。その力を組織として育てられるかどうかが、生成AI活用の成否を分ける重要なポイントになるでしょう。

















コメント